从宿主机获得Docker内部IP
在Docker内部获取IP
Docker内部里面,ipconfig/ip 等命令是无法使用的,正确的命令是
$ hostname -I
172.24.116.11在宿主机获得Docker的IP
假设你已经有了一个Docker,ID是f864187a2406
$ docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' f864187a2406
172.24.116.11
$ docker inspect --format '{{ .NetworkSettings.IPAddress }}' f864187a2406
172.24.116.11
$ docker inspect f864187a2406 | egrep -e "(IPAddress|Id)"
"Id": "f864187a24065636dc0cf9e87bdf2971fea27d4014cf981eaac6b971506b2776",
"deployId": "8747",
"SecondaryIPAddresses": null,
"IPAddress": "172.24.116.11",
"IPAddress": "172.24.116.11",在Linux下转换unix时间戳
在Linux下转换unix时间戳是非常容易的事情, 用date命令就可以实现.
$ date -d @1576806092
Fri Dec 20 09:41:32 CST 2019Prometheus的label处理
Prometheus能否在查询的时候对label进行2次处理呢?答案是可以的。Prometheus提供了一系列函数可以在Query的时候进行二次处理,本文要介绍的函数是label_replace()。
我们都知道,在 Prometheus 的配置文件里,不论targets里的ip是否带了:9100,最终形成的instance里面都会给你带上这个端口,形成像192.168.1.1:9100这样的格式。这个 instance本身就是一个 Prometheus 内置的label(这里指192.168.1.1:9100)。今天我们演示一下把讨厌的:9100去掉。
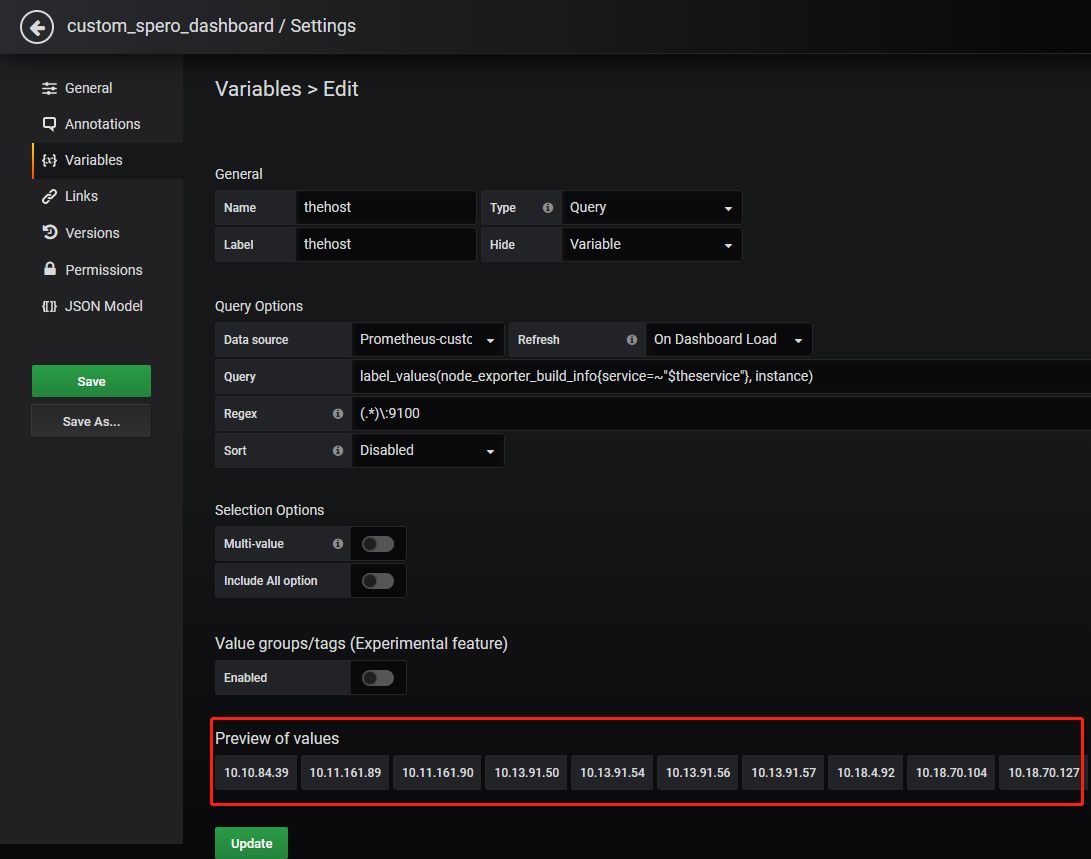
虽然我们也可以使用Variables功能来对instance进行正则化处理(如下图),但是处理以后的结果,在dashboard里面无法选中单个主机。因此这种方法是有bug的(不推荐使用)。
Prometheus add custom exporter
Prometheus(中文名:普罗米修斯)是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB). 使用Go语言开发, 基本原理是通过HTTP协议周期性抓取被监控组件的状态. Prometheus获取数据的策略是Pull而不是Push, 也就是说, 它会自己去抓取, 而不用你来推送. 抓取使用的是HTTP协议, 在配置文件中指定目标程序的端口, 路径及间隔时间即可.
目前互联网公司常用的组件大部分都有exporter可以直接使用, 比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等).
当Prometheus的node_exporter中没有我们需要的一些监控项时,就可以如zabbix一样添加一些自定义的metrics,让其支持我们所需要的监控项。node_exporter 可在启动时指定路径,并将该路径下的 *.prom 识别为监控数据文件。
准备获取metrics的脚本
$ cat /opt/monitor/get_info.sh
#! /bin/bash
echo Logical_CPU_core_total `cat /proc/cpuinfo| grep processor| wc -l`
echo logined_users_total `who | wc -l`;
echo procs_total `ps aux|wc -l`
echo procs_zombie `ps axo pid=,stat=|grep Z|wc -l`测试脚本执行情况
$ bash get_info.sh
Logical_CPU_core_total 2
logined_users_total 1
procs_total 148
procs_zombie 0设置定时任务
* * * * * bash /opt/monitor/get_info.sh > /opt/monitor/get_info.prom启动 node_exporter
启动 node_exporter 时指定*.prom 数据文件的路径
./node_exporter --collector.textfile.directory=/opt/monitor/验证metrics
$ curl 127.0.0.1:9100/metrics|grep -E Logical_CPU_core_total|logined_users_total|procs_total|procs_zombie
# TYPE Logical_CPU_core_total untyped
Logical_CPU_core_total 2
# HELP logined_users_total Metric read from /opt/monitor/get_info.prom
# TYPE logined_users_total untyped
logined_users_total 1
# HELP procs_total Metric read from /opt/monitor/get_info.prom
# TYPE procs_total untyped
procs_total 151
# HELP procs_zombie Metric read from /opt/monitor/get_info.prom
# TYPE procs_zombie untyped
procs_zombie 0参考文档:
Prometheus 自定义exporter 监控key
logstash的drop过滤器插件
logstash在filter段对日志进行解析的时候, 可以直接筛选出我们想要的日志内容, 如果日志内容里不包括某些字段, 我们可以把整条日志直接扔掉, 下面是配置.
input {
kafka {
bootstrap_servers => k1.zhukun.net:6687 k2.zhukun.net:6687
topics => ["com.prod.feedengine","com.prod.feedgateway"]
# 如果收取多个kafaka topic里的消息也可以用下面的写法
# topics_pattern => "zhukun.net.log.rms-api.*"
group_id => logstash-mp-ops
consumer_threads => 10
decorate_events => true
auto_offset_reset => "latest"
}
}
filter {
# 如果message里不以2019/2020/2021开头, 则直接丢弃整条日志
if [message] !~ /^[2020|2021|2019]/ {
drop { }
}
# 直接打印出来原始日志看看
#ruby {
# code => 'puts event(message)'
#}
# grop正则匹配
grok {
match => { message => '%{TIMESTAMP_ISO8601:time_local}\s*\[%{DATA:service}\]\s*%{LOGLEVEL:loglevel}\s*%{DATA:message}$' }
overwrite => [message]
tag_on_failure => ["_invalid_log_format"] # 如果解析失败则加上这个tag
}
# 如果日志解析成功,那么
if !("_invalid_log_format" in [tags]) {
mutate {
# 如果把整条日志都解析出来以后(已经解析到各个tag之中), 原始日志应该也没什么用了, 可以考虑直接扔掉原始日志
remove_field => [ "message" ]
# 将kafka topic的名字作为oootype字段
add_field => { "oootype" => "%{[@metadata][kafka][topic]}" }
gsub => [
"logInfo", "\t\t", ""
]
}
# 日期处理
date {
# 将time_local赋给@timestamp字段, 右侧是time_local的实际格式, 例如2019-03-18 08:12:45.006
match => ["time_local", "yyyy-MM-dd HH:mm:ss.SSS"]
# match => [ "logTime", "ISO8601" ]
# timezone => "Asia/Shanghai"
target => "@timestamp" # 默认target就是@timestamp
tag_on_failure => [ "_dateparsefailure" ]
# remove_field => [ "time_local" ]
}
}
}
output {
elasticsearch {
hosts => [10.18.4.24:9200,10.18.4.25:9200,10.18.4.77:9200,10.18.4.78:9200, 10.11.149.69:9200,10.16.22.149:9200]
index => zhukun.net_console.log-%{+yyyy.MM.dd}
}
#stdout {
# codec => rubydebug {
# metadata => true
# }
#}
}补充:
logstash可以使用条件判断来控制filter的执行。官方说明见Accessing Event Data and Fields in the Configuration。支持的运算符包括:
相等: ==, !=, <, >, <=, >=
正则: =~(匹配正则), !~(不匹配正则)
包含: in(包含), not in(不包含)
布尔操作: and(与), or(或), nand(非与), xor(非或)
一元运算: !(取反), ()(复合表达式), !()(对复合表达式结果取反)参考文档
Drop filter plugin
Logstash Grep and Drop
Missing grep filter in logstash
